Table of Contents
Google Summer of Code 2010: Sahana OCR
Exclusive Summary
- Abstract : The data collecting and entering process can be considered as one of the most pain full exercises with manual handling during a huge disaster situation. Therefore Sahana OCR is recognised as a great tool in solving such problems. When it comes to OCR module, reliability and consistency are major areas to be addressed. By focusing and improving these two characteristics, Sahana OCR module can be optimally utilised when ever, where ever a disaster situation occurred.
- Current Status : During a past disaster situation the data are collected from the distributed forms to the victims, which is the most successful method of data collecting within a disaster situation. Then the Sahana OCR module scans these forms using ScannerManager and sends them to create the form images. The form images then processed to extract the data fields and then the letter boxes within the data fields using FormProcessor and the ImageProcessor. Currently the character recognition task was done by a Neural network developed using FANN library. But the accuracy of the recognition was very poor since lack of training the neural network.
Following data about the current status has taken from the document which was written at the last years Gsoc session by Gihan Chamara.
Design :
There were several facts was considered when designing the system
- Separate platform depending components from independent.
- Accommodate future upgrades to major components independently.
- Independent from application form.
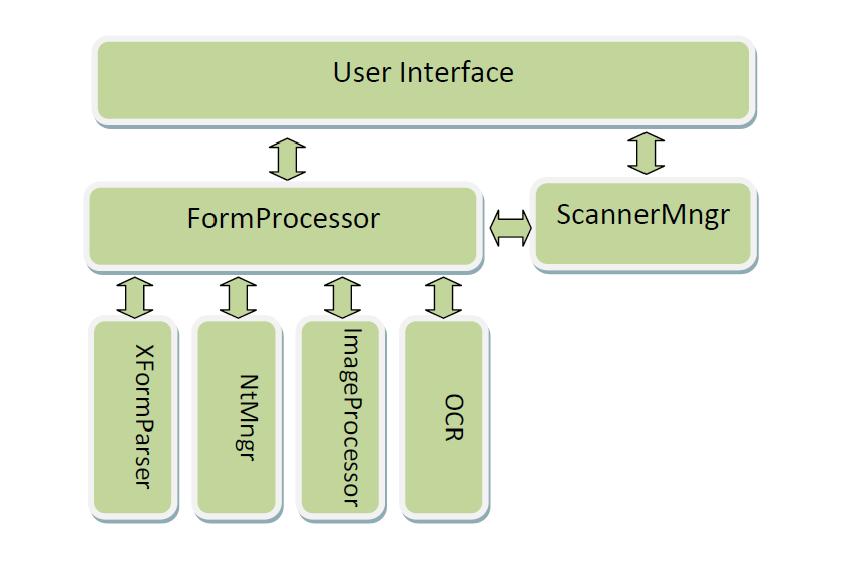

Process :
XForm is loaded into memory. Then, image from scanner or disk is loaded into memory. FormProcessor preprocess, aligned the image and segmented using ImageProcessor library. Segmented letters are passed to OCR and with OCR result FormProcessor create result XML. Result XML is passed to NtMnger and uploaded to server. Before uploading, user can evaluate and do any necessary correction. Following figure shows the overall process graphically.

Current implementation : In current implementation, application was developed to run on Microsoft windows platform and the .Net 2.0 framework. XFormparser , Imageprocessor and scannerMgr are completed and OCR and User interface are partially developed.
XFormParser:
This is the part that handle XForm XMLs, and the component is consist of following classes
- XForm
- XFormParser
- DataField
- TextArea
- XFormDomErrorHandler
This module load xml file into the type of xform data structure in memory. Later XForm structure is used by Form processor to segment the scanned image. Module was implemented using Xerces open source XML library.
ImageProcessor: All image processing methods was enclosed in to this component. Main objective is to segment the scanned image into letters. Currently all necessary image processing need to segment and page aligning has implemented using OpenCV open source Vision library. Most of the methods had coded by the earlier developers.
OCR:
The most critical component in the system. Earlier this was done using artificial neural network. But it was able to recognize digits only. FANN framework has used for efficient neural network implementation. In current system I also used the earlier OCR with some modifications. But, Still not working properly. We need some context recognition and some dictionary lookup.
ScannerMngr:
This is wrapper module for Twain API. This library provides functions to enquiry available scanners, connect to required scanner, configure and view scanner properties. Then application can continuously scan if the scanner supports auto feed otherwise one by one. This component is completed with required functionality.
NtMngr:
This component deal with the network. Main functionalities are downloading correct XForm XML from server and Uploading result to the server. For a given path, it loads the XML that contains the details about the server and available XForms, in order to user can select proper XForm from available list. Also this module has to handle Proxy servers, if there is any. This component has to be developed. Currently XML is read form disk.
FormProcessor :
This is the class that coordinates all the above components. This part has been completed. FormProcessor segments image according to XForm using Imageprocessor library, then pass those segmented images to the OCR and create Result XML with result of OCR. Finally result XML will upload to the server through NtMnger module.
MainApplication:
User friendly interface with several views. Interface is partially completed.
SahanaOCR Application
Current application can scan image, load XForm Xml from disk and then process the scan image. But logging and progress views yet not completed.
When application starts, user has to select correct scanner from the list of available scanners or a folder that contains scanned images from disk. zIf needed, user can change or see the configurations of the scanner. Then, correct XForm XML has to be selected. When user enter correct server path it will list available XForms. Then he can select proper one or he can select XForm from Disk.
After selecting scanner and XForm, user can start processing forms one by one or continuously, if scanner supports auto paper feeding. User can set direct uploading or buffer processed forms until he evaluate manually and correct any mistakes made by OCR.
ScreenShots




- Student : Thilanka Kaushalya.
- Mentor(s) : Gihan Chamara , Jo Fonseka, Chamindra de Silva, and Hayesha Somorathne.
Code
Progress
- I have tested the Tesseract using with the existing system and manage to get a good accuracy of recognizing the data.Sample Code
- I have followed the training process of Tesseract to measure the ability to train it for handwritten letters. Testing Results
Project plan and Timeline
- Basically my project plan is organize the SahanaOCR module as a complete module which can handle the whole process of the data entering, with a great accuracy.
The basic project ideas are as follows.
- Integrate the Tesseract code to the project.
- Differentiate the forms and the pages from each other and identify them by the system itself to automate the data sending process to the corresponding modules.
- Make the system platform independent.
These are timeline which are allocated to specific tasks.
| Officially coding period has started on 24th May | |||
|---|---|---|---|
| Goal | Measure | Due date | Status |
| Integrating Tesseract with the SahanaOCR | Accurately recognize the letters by the system using Tesseract | 06/20/2010 | Completed |
| Training Tesseract for handwritten charactes | Accurately recognize the handwritten characters by the system using Tesseract | 06/30/2010 | Not yet completed (Training Process has completely done but the accuracy was not that much improved. So have to try again) |
| Developing UI for the Sahana OCR system | Can handle the all the processes by UI | 07/12/2010 | Not yet Completed |
| Midterm Evaluation from 12th July to 16th July | |||
|---|---|---|---|
| Modify the FormProcessor and ImageProcessor to identify forms | Correctly identify each form and process them according to its structure | 07/25/2010 | Not Yet Complete |
| Implement the data handling section with the other modules | Correctly send the recognized data from the OCR module to related module | 08/10/2010 | Not Yet Complete |
- The weekly meetings are scheduled on Saturdays at 1530 UTC. Calender
- Weekly report will be sent to the mentor and the mailing list on every Saturday, which contains the progress of the project during that week.